)
目录
- 已开发项目效果实现截图
- 已开发项目效果实现截图
- 开发技术
- 系统开发工具:
- 核心代码参考示例
- 1.建立用户稀疏矩阵,用于用户相似度计算【相似度矩阵】
- 2.计算目标用户与其他用户的相似度
- 系统测试
- 总结
- 源码文档获取/同行可拿货,招校园代理 :文章底部获取博主联系方式!
- 开发技术
- 系统开发工具:
- 核心代码参考示例
- 1.建立用户稀疏矩阵,用于用户相似度计算【相似度矩阵】
- 2.计算目标用户与其他用户的相似度
- 系统测试
- 总结
- 源码文档获取/同行可拿货,招校园代理 :文章底部获取博主联系方式!
已开发项目效果实现截图
同行可拿货,招校园代理
已开发项目效果实现截图
同行可拿货,招校园代理
开发技术
本系统(程序+源码+数据库+调试部署+讲解)同时还支持java、ThinkPHP、Node.js、Spring Boot、SSM、Springcloud 带文档1万字以上 有源码 程序 和表结构sql文档,开发工具:IntelliJ IDEA,VScode;数据库管理软件:Navicat;开发技术框架:MyBatis,Spring Boot,Vue;采用B/S架构,使用Maven作为项目管理工具前后端分离项目使用vue.js+ElementUi+Springboot+Mysql做整合开发 ,前端页面数据处理传输以及页面展示使用Vue技术
前端开发框架:vue.js
数据库 mysql 版本不限
后端语言框架支持:
1 java(SSM/springboot)-idea/eclipse
2.Nodejs+Vue.js -vscode
3.python(flask/django)–pycharm/vscode
4.php(thinkphp/laravel)-hbuilderx
JDK版本不限,最低jdk1.8
技术栈:JAVA+Mysql+Springboot+Vue+Maven
数据库工具:Navicat/SQLyog都可以
数据库:mysql (版本不限)
系统开发工具:
Vue 是一套用于构建用户界面的渐进式框架。与其它大型框架不同的是,Vue 被设计为可以自底向上逐层应用。Vue 的核心库只关注视图层,不仅易于上手,还便于与第三方库或既有项目整合。另一方面,当与现代化的工具链以及各种支持类库结合使用的,Vue也能够为复杂的单页应用提供驱动。
Mysql简介:
数据库是学习开发过程中必不可少的一部分,有很多的企业也正在使用Mysql,平时的开发学习也离不开它,能节约很多成本,并且性能要求不高,是中小型企业的首选。
IDEA介绍:
IntelliJ IDEA是java编程语言的集成环境,目前是业界公认的最好的开发工具,他拥有使用的自动导包、代码提示、一键重置等功能,并拥有全世界的程序员贡献的各种强大的插件,辅佐人们更好的开发,内部继承Maven管理、git工具等让开发变得更便捷。
前端开发:使用HTML、CSS、JavaScript等前端开发语言和微信小程序框架,实现界面设计和用户交互功能。
后端开发:选择合适的后端开发语言和框架,如Node.js、Django、Spring Boot等,处理业务逻辑和数据交互。
数据库设计:设计数据库表结构,选择合适的数据库管理系统,如MySQL、MongoDB等,实现数据库操作。
系统部署与测试:将前端代码部署到微信小程序平台,部署后端服务到云服务器或其他托管平台,进行系统整体测试和优化。
核心代码参考示例
1.建立用户稀疏矩阵,用于用户相似度计算【相似度矩阵】
协同过滤算法代码如下(示例):
/** * 协同过滤算法 */publicUserBasedCollaborativeFiltering(Map<String,Map<String,Double>>userRatings){this.userRatings=userRatings;this.itemUsers=newHashMap<>();this.userIndex=newHashMap<>();//辅助存储每一个用户的用户索引index映射:user->indexthis.indexUser=newHashMap<>();//辅助存储每一个索引index对应的用户映射:index->user// 构建物品-用户倒排表intkeyIndex=0;for(Stringuser:userRatings.keySet()){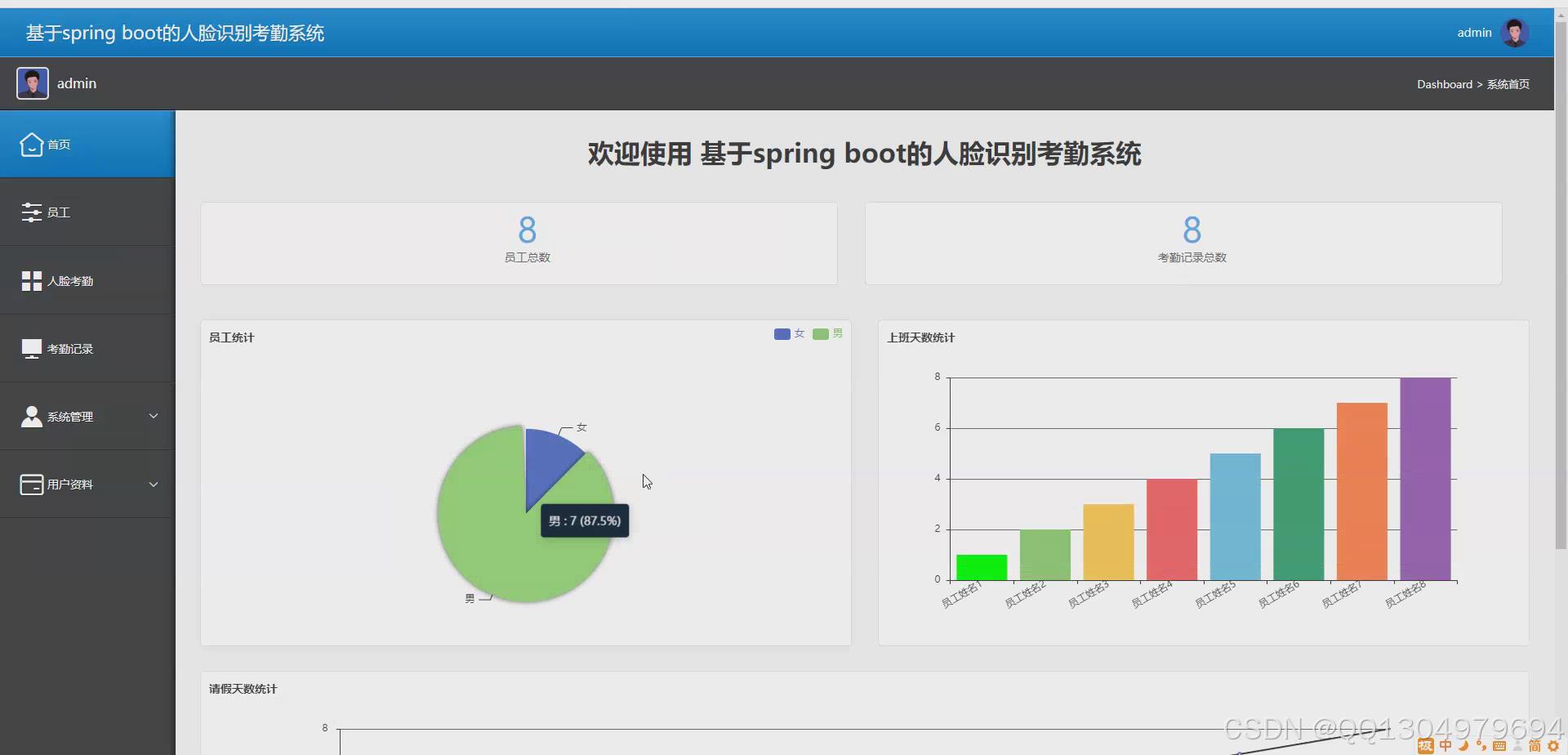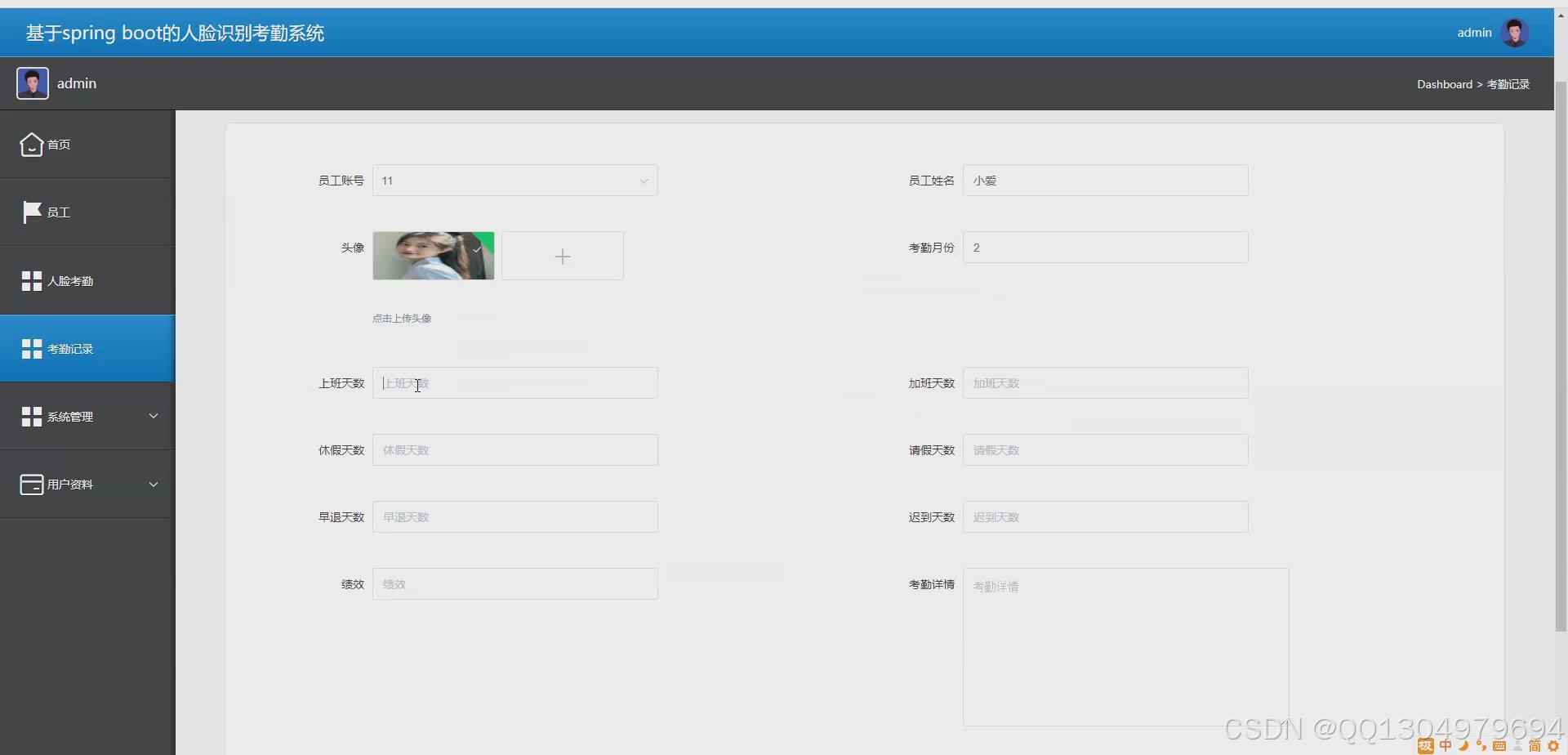Map<String,Double>ratings=userRatings.get(user);for(Stringitem:ratings.keySet()){if(!itemUsers.containsKey(item)){itemUsers.put(item,newArrayList<>());}itemUsers.get(item).add(user);}//用户ID与稀疏矩阵建立对应关系this.userIndex.put(user,keyIndex);this.indexUser.put(keyIndex,user);keyIndex++;}intN=userRatings.size();this.sparseMatrix=newLong[N][N];//建立用户稀疏矩阵,用于用户相似度计算【相似度矩阵】for(inti=0;i<N;i++){for(intj=0;j<N;j++)this.sparseMatrix[i][j]=(long)0;}for(Stringitem:itemUsers.keySet()){List<String>userList=itemUsers.get(item);for(Stringu1:userList){for(Stringu2:userList){if(u1.equals(u2)){continue;}this.sparseMatrix[this.userIndex.get(u1)][this.userIndex.get(u2)]+=1;}}}}publicdoublecalculateSimilarity(Stringuser1,Stringuser2){//计算用户之间的相似度【余弦相似性】Integerid1=this.userIndex.get(user1);Integerid2=this.userIndex.get(user2);if(id1==null||id2==null)return0.0;returnthis.sparseMatrix[id1][id2]/Math.sqrt(userRatings.get(indexUser.get(id1)).size()*userRatings.get(indexUser.get(id2)).size());}2.计算目标用户与其他用户的相似度
publicList<String>recommendItems(StringtargetUser,intnumRecommendations){// 计算目标用户与其他用户的相似度Map<String,Double>userSimilarities=newHashMap<>();for(Stringuser:userRatings.keySet()){if(!user.equals(targetUser)){doublesimilarity=calculateSimilarity(targetUser,user);userSimilarities.put(user,similarity);}}// 根据相似度进行排序List<Map.Entry<String,Double>>sortedSimilarities=newArrayList<>(userSimilarities.entrySet());sortedSimilarities.sort(Map.Entry.comparingByValue(Comparator.reverseOrder()));// 选择相似度最高的K个用户List<String>similarUsers=newArrayList<>();for(inti=0;i<numRecommendations;i++){if(i<sortedSimilarities.size()){similarUsers.add(sortedSimilarities.get(i).getKey());}else{break;}}// 获取相似用户喜欢的物品,并进行推荐Map<String,Double>recommendations=newHashMap<>();for(Stringuser:similarUsers){Map<String,Double>ratings=userRatings.get(user);for(Stringitem:ratings.keySet()){if(userRatings.get(targetUser)!=null&&!userRatings.get(targetUser).containsKey(item)){recommendations.put(item,ratings.get(item));}}}系统测试
系统测试是一项人工或自动化的过程,主要是对系统的功能进行测试,确定测试的实际结果与预期的结果之间的差异。在开发的系统还没有正式的使用之前,为了确保该系统能够满足各种需求,必须对其进行全面的系统测试,以验证其功能是否符合预期并正常运行[15]。功能需求就是系统在功能上的需求,对用户来说功能需求最为现实,而用户使用软件的最大原因之一恰恰就是软件能满足用户使用需求,能帮助用户实现一些具体功能,这样就节约了时间和提高了效率。只有正视需求分析的重要性,才能让开发出来的软件产品满足客户的需求。在软件刚开始开发的时候,需要对用户进行需求调研,了解系统功能和用户需求,归纳和分析,写出系统需求文档,以规范开发工作,提高开发效率
总结
采用 SpringBoot 框架进行后端设计和开发,以确保平台的稳定性和可扩展性。前端基于Vue.js+Element UI构建组件化界面,降低跨平台适配开发成本。使用 Idea 开发工具和 MVC 模式,实现前后端分离,提高开发效率和代码可维护性。使用 MySQL 数据库对数据进行存储和管理,保障数据的安全性和可靠性。使用测试工具通过对平台进行功能测试、性能测试和用户体验测试,发现并修复系统中的缺陷,优化系统性能。采用 Maven 等项目管理工具来创建系统项目并管理依赖,保证项目结构的规范与依赖的有效管理
(1)系统应符合课题系统的规定,满足网站相关人员日常使用的需要,并达到操作过程中的直观,方便,实用,安全等要求;
(2)系统采用模块化程序设计方法,既便于系统功能的各种组合和修改,又便于未参与开发的技术维护人员补充,维护;
(3)系统应具备数据库维护功能,及时根据用户需求进行数据的添加、删除、修改、备份等操作;
(4)尽量采用现有软件环境及先进的管理系统开方案,从而达到充分利用现有资源,提高系统开发水平和应用效果的目的。
源码文档获取/同行可拿货,招校园代理 :文章底部获取博主联系方式!
需要成品或者定制,加我们的时候,不满意的可以定制
文章最下方名片联系我即可~ 所有项目都经过测试完善,本系统包修改时间和标题,包安装部署运行调试
](https://i-blog.csdnimg.cn/direct/6dd2892aa4df4354ade31f0587300052.jpeg#pic_center)
开发技术
本系统(程序+源码+数据库+调试部署+讲解)同时还支持java、ThinkPHP、Node.js、Spring Boot、SSM、Springcloud 带文档1万字以上 有源码 程序 和表结构sql文档,开发工具:IntelliJ IDEA,VScode;数据库管理软件:Navicat;开发技术框架:MyBatis,Spring Boot,Vue;采用B/S架构,使用Maven作为项目管理工具前后端分离项目使用vue.js+ElementUi+Springboot+Mysql做整合开发 ,前端页面数据处理传输以及页面展示使用Vue技术
前端开发框架:vue.js
数据库 mysql 版本不限
后端语言框架支持:
1 java(SSM/springboot)-idea/eclipse
2.Nodejs+Vue.js -vscode
3.python(flask/django)–pycharm/vscode
4.php(thinkphp/laravel)-hbuilderx
JDK版本不限,最低jdk1.8
技术栈:JAVA+Mysql+Springboot+Vue+Maven
数据库工具:Navicat/SQLyog都可以
数据库:mysql (版本不限)
系统开发工具:
Vue 是一套用于构建用户界面的渐进式框架。与其它大型框架不同的是,Vue 被设计为可以自底向上逐层应用。Vue 的核心库只关注视图层,不仅易于上手,还便于与第三方库或既有项目整合。另一方面,当与现代化的工具链以及各种支持类库结合使用的,Vue也能够为复杂的单页应用提供驱动。
Mysql简介:
数据库是学习开发过程中必不可少的一部分,有很多的企业也正在使用Mysql,平时的开发学习也离不开它,能节约很多成本,并且性能要求不高,是中小型企业的首选。
IDEA介绍:
IntelliJ IDEA是java编程语言的集成环境,目前是业界公认的最好的开发工具,他拥有使用的自动导包、代码提示、一键重置等功能,并拥有全世界的程序员贡献的各种强大的插件,辅佐人们更好的开发,内部继承Maven管理、git工具等让开发变得更便捷。
前端开发:使用HTML、CSS、JavaScript等前端开发语言和微信小程序框架,实现界面设计和用户交互功能。
后端开发:选择合适的后端开发语言和框架,如Node.js、Django、Spring Boot等,处理业务逻辑和数据交互。
数据库设计:设计数据库表结构,选择合适的数据库管理系统,如MySQL、MongoDB等,实现数据库操作。
系统部署与测试:将前端代码部署到微信小程序平台,部署后端服务到云服务器或其他托管平台,进行系统整体测试和优化。
核心代码参考示例
1.建立用户稀疏矩阵,用于用户相似度计算【相似度矩阵】
协同过滤算法代码如下(示例):
/** * 协同过滤算法 */publicUserBasedCollaborativeFiltering(Map<String,Map<String,Double>>userRatings){this.userRatings=userRatings;this.itemUsers=newHashMap<>();this.userIndex=newHashMap<>();//辅助存储每一个用户的用户索引index映射:user->indexthis.indexUser=newHashMap<>();//辅助存储每一个索引index对应的用户映射:index->user// 构建物品-用户倒排表intkeyIndex=0;for(Stringuser:userRatings.keySet()){Map<String,Double>ratings=userRatings.get(user);for(Stringitem:ratings.keySet()){if(!itemUsers.containsKey(item)){itemUsers.put(item,newArrayList<>());}itemUsers.get(item).add(user);}//用户ID与稀疏矩阵建立对应关系this.userIndex.put(user,keyIndex);this.indexUser.put(keyIndex,user);keyIndex++;}intN=userRatings.size();this.sparseMatrix=newLong[N][N];//建立用户稀疏矩阵,用于用户相似度计算【相似度矩阵】for(inti=0;i<N;i++){for(intj=0;j<N;j++)this.sparseMatrix[i][j]=(long)0;}for(Stringitem:itemUsers.keySet()){List<String>userList=itemUsers.get(item);for(Stringu1:userList){for(Stringu2:userList){if(u1.equals(u2)){continue;}this.sparseMatrix[this.userIndex.get(u1)][this.userIndex.get(u2)]+=1;}}}}publicdoublecalculateSimilarity(Stringuser1,Stringuser2){//计算用户之间的相似度【余弦相似性】Integerid1=this.userIndex.get(user1);Integerid2=this.userIndex.get(user2);if(id1==null||id2==null)return0.0;returnthis.sparseMatrix[id1][id2]/Math.sqrt(userRatings.get(indexUser.get(id1)).size()*userRatings.get(indexUser.get(id2)).size());}2.计算目标用户与其他用户的相似度
publicList<String>recommendItems(StringtargetUser,intnumRecommendations){// 计算目标用户与其他用户的相似度Map<String,Double>userSimilarities=newHashMap<>();for(Stringuser:userRatings.keySet()){if(!user.equals(targetUser)){doublesimilarity=calculateSimilarity(targetUser,user);userSimilarities.put(user,similarity);}}// 根据相似度进行排序List<Map.Entry<String,Double>>sortedSimilarities=newArrayList<>(userSimilarities.entrySet());sortedSimilarities.sort(Map.Entry.comparingByValue(Comparator.reverseOrder()));// 选择相似度最高的K个用户List<String>similarUsers=newArrayList<>();for(inti=0;i<numRecommendations;i++){if(i<sortedSimilarities.size()){similarUsers.add(sortedSimilarities.get(i).getKey());}else{break;}}// 获取相似用户喜欢的物品,并进行推荐Map<String,Double>recommendations=newHashMap<>();for(Stringuser:similarUsers){Map<String,Double>ratings=userRatings.get(user);for(Stringitem:ratings.keySet()){if(userRatings.get(targetUser)!=null&&!userRatings.get(targetUser).containsKey(item)){recommendations.put(item,ratings.get(item));}}}系统测试
系统测试是一项人工或自动化的过程,主要是对系统的功能进行测试,确定测试的实际结果与预期的结果之间的差异。在开发的系统还没有正式的使用之前,为了确保该系统能够满足各种需求,必须对其进行全面的系统测试,以验证其功能是否符合预期并正常运行[15]。功能需求就是系统在功能上的需求,对用户来说功能需求最为现实,而用户使用软件的最大原因之一恰恰就是软件能满足用户使用需求,能帮助用户实现一些具体功能,这样就节约了时间和提高了效率。只有正视需求分析的重要性,才能让开发出来的软件产品满足客户的需求。在软件刚开始开发的时候,需要对用户进行需求调研,了解系统功能和用户需求,归纳和分析,写出系统需求文档,以规范开发工作,提高开发效率
总结
采用 SpringBoot 框架进行后端设计和开发,以确保平台的稳定性和可扩展性。前端基于Vue.js+Element UI构建组件化界面,降低跨平台适配开发成本。使用 Idea 开发工具和 MVC 模式,实现前后端分离,提高开发效率和代码可维护性。使用 MySQL 数据库对数据进行存储和管理,保障数据的安全性和可靠性。使用测试工具通过对平台进行功能测试、性能测试和用户体验测试,发现并修复系统中的缺陷,优化系统性能。采用 Maven 等项目管理工具来创建系统项目并管理依赖,保证项目结构的规范与依赖的有效管理
(1)系统应符合课题系统的规定,满足网站相关人员日常使用的需要,并达到操作过程中的直观,方便,实用,安全等要求;
(2)系统采用模块化程序设计方法,既便于系统功能的各种组合和修改,又便于未参与开发的技术维护人员补充,维护;
(3)系统应具备数据库维护功能,及时根据用户需求进行数据的添加、删除、修改、备份等操作;
(4)尽量采用现有软件环境及先进的管理系统开方案,从而达到充分利用现有资源,提高系统开发水平和应用效果的目的。
源码文档获取/同行可拿货,招校园代理 :文章底部获取博主联系方式!
需要成品或者定制,加我们的时候,不满意的可以定制
文章最下方名片联系我即可~ 所有项目都经过测试完善,本系统包修改时间和标题,包安装部署运行调试




